Web Kazımında Etik
Çeviri|
Hepimiz webde veri kazıyoruz. Özellikle veri ile çalışanlar diyeyim. Veri bilimciler, pazarlamacılar, veri gazeteciler, ve veri meraklıları. Bu teknikten kolayca yararlanabiliyor olmak etiği hakkında biraz daha fazla düşünmemi sağladı ve konuyla ilgili bir fikir birliği de göremediğim için üzerine yazmak istedim.
Yasalardan değil ama etikten bahsediyorum esasen. Yasal boyutunu da dahil edince webden veri kazıma kompleks bir duruma dönüşebiliyor. Bu konu üzerine fazla düşünülmediği için ya da üzerine bir şeyler yazılmadığı için değil; hem kazıma işlemi hem de kazımanın yapılması sürecinde hiçbir taraf temel prensiplerde aynı fikirde değil maalesef. Bu açıdan karmaşık bir hale gelebiliyor.
Ben bu konun iki tarafında da yer alıyorum. Ağırlıkta kişisel projelerim için veri kazıyorum ayrıca işimde de veri toplamak için aynı şeyi yapıyorum. Diğer taraftan ise, “botları” nasıl filtelerim diye kendimle çok mücadele ediyor ya da gerçek müşterilere odaklanmak için işverenin web analitiği için çalışmam gerekebiliyor.
Veri kazıma bu bağlamda hayatımın merkezine yerleşti, savaşmak yerine bazı temel kurallar koymak gerekiyor. Aşağıda benim tecrübelerim üzerinden yaptığım bir kurallar listesi var ama bunların tabii ki eksiği de var.
Etik Kazıyıcı Olma
Web kazıyıcı olarak ben aşağıdaki prensipleri uyguluyorum:
- Aradığım verileri sağlayan genel bir API’ya sahibiyseniz, sadece onu kullanacağım ve hepsini birlikte kazımayacağım.
- Niyetimi açıkça göstereceğim, bana sorularınızı ve kaygılarınızı dile getirmeniz için iletişim bilgisi sunacağım.
- Verileri makul bir oranda talep edeceğim (kazıyacağım). DDoS saldırısına dönüşmemesi için gayret göstereceğim.
- Sitenizden sadece ihtiyacım olan veriyi saklayacağım. Eğer OpenGraph meta verilerine ihtiyacım varsa, tutacağım bu kadar.
- Tuttuğum içeriğe saygı duyacağım. Benim içeriğimmiş gibi göstermeyeceğim.
- Size bir faydası olmasının yollarına bakacağım. Belki sitenize gerçek bir trafik oluştur ya da sitenizi bir içerikte ya da makalede referanslarım.
- Verileri çoğaltmak için değil, verilerden yeni değer yaratmak için kazıyacağım
Etik Site Sahibi Olma
Site sahibi olarak şu prensipleri uyguluyorum:
- Sitemin performansını düşürmedikleri sürece etik kazıyıcıların siteme erişimine izin vereceğim.
- Onları engelleyen gizli kazıyıcıların kullanımını teşvik etmektense, şeffaf olan kullanıcı tarayıcılarına saygı göstereceğim.
- Kalıcı olarak engellememek için kazıyıcının sahibine ulaşacağım ( Etik Tarayıcı Kullanıcı dizesi sayesinde) Site performansı veya ahlaki kaygı durumunda geçici bir blok kabul edilebilir.
- Kazıyıcıların açık webin gerçeği olduğunu anlıyorum.
- Kazıyıcılara alternatif olarak veri sağlamak için API’ları göz önünde bulunduracağım.
Bu Bizi Nereye Taşır?
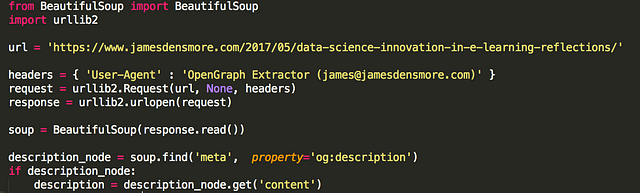
Konu şu ki veri kazımak kolay. Python’da birkaç satır ya da urllib2 ( ya da istediğiniz) ya da BeautifulSoup gibi harika kitaplıkların yardımıyla bir sayfanın HTML sayfasını toplayıp ayrıştırabilirsiniz.
Tabii ki bir hafta sonu projeniz için birkaç bin blog yazısını kazımak hiç sorun değil. Bence iş için yapılan kazıma da etik şekilde rahatlıklar yapılabilir. En dikkat çeken ticari amaçlı yoğun web sitesi kazıma süreçleri ve bu süreçler riskler de yaratıyor,- hele ki bizim gibi yenilik yapma, öğrenme ve yeniden değer yaratma gibi geniş bir hedefi kapsıyor ise. Biraz saygı ile daha iyi sürdürülebilir işler yapabiliriz.
Kaynak: https://medium.com/towards-data-science/ethics-in-web-scraping-b96b18136f01
Veri Gazeteciliği Platformu (www.verigazeteciligi.com) sitesinde yayınlanan haber, makale, rapor ve çeviriler genellikle telif hakkına sahip olunan çalışmalardır. Kullanımı için  lisansı dikkate alınmalıdır.
lisansı dikkate alınmalıdır.